- Je levert een CSV-export aan die per collectie-item een aantal velden bevat.
Hoe meer schone en correcte data in de export zit die je uit je beheersysteem haalt, hoe kwalitatiever de resultaten van de tool. Het loont dus de moeite om indien nodig je data op te schonen voor een valide CSV-bestand en een goed resultaat. - Als je CSV-bestand valide is (zie verder), matcht de tool de vervaardigers van jouw collectiestukken met items in Wikidata.
Daarbij houdt de tool rekening met het type collectiestuk waarvan je data aanlevert. Als het om een schilderij gaat, zal de tool bv. primair zoeken naar schilders in Wikidata.
Tip: om de validatie te vergemakkelijken is het best om zo veel mogelijk beschikbare metadata over de vervaardigers mee aan te leveren in je csv-export. Denk aan geboorte- en sterfdata, maar maar ook externe identifiers (VIAF, ULAN en RKD) die eventueel al in jouw beheersysteem zijn opgenomen. - Even later krijg je een verrijkt CSV-bestand in je mailbox.
- In dat CSV-bestand kan je de voorgestelde matches goedkeuren of afwijzen.
- Vervolgens laad je het bijgewerkte CSV-bestand opnieuw op.
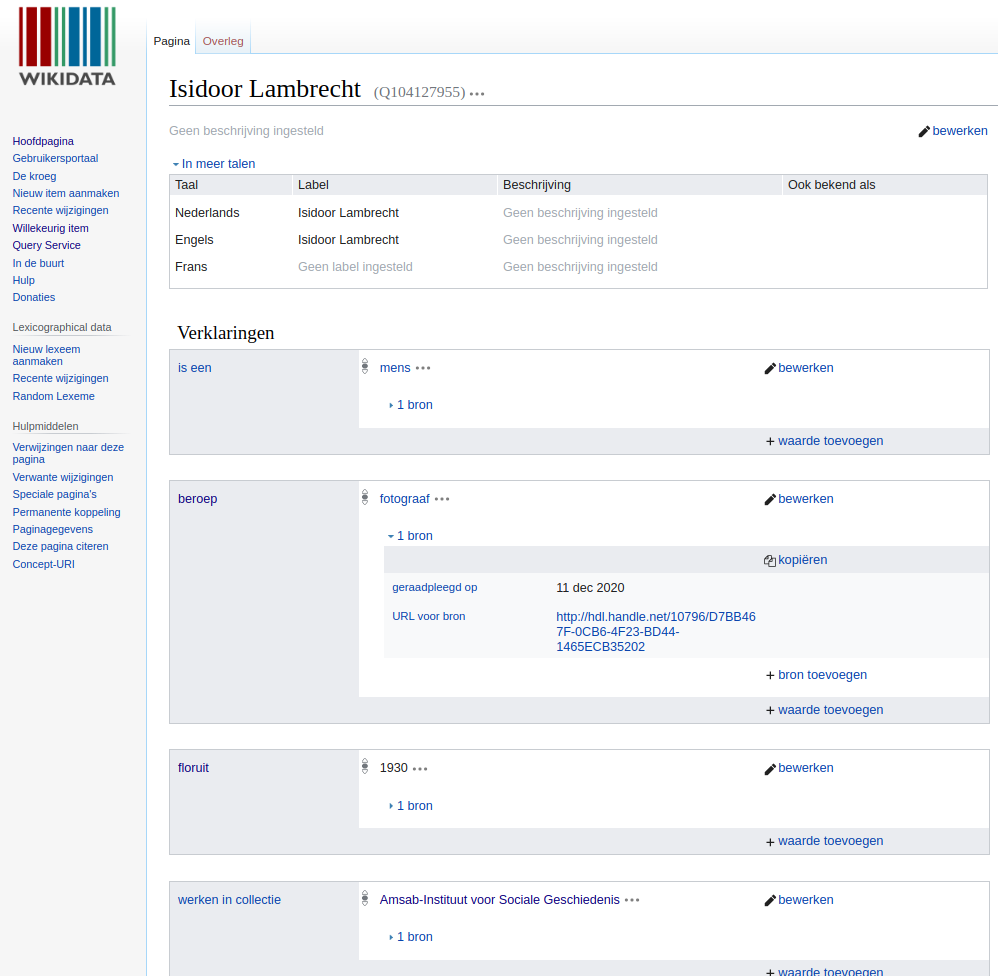
- De tool zal vervolgens aan de hand van het eventuele sterfjaar, de geboortedatum en de creatiedatum bepalen of een collectiestuk al dan niet nog auteursrechtelijk beschermd is. Tegelijk zal eventuele extra informatie uit jouw CSV-bestand naar Wikidata geschreven worden, om zo de kwaliteit van toekomstige matchings te verbeteren. Het is dus belangrijk dat je data correct en schoon is. Een voorbeeld van een aangemaakt item op basis van aangeleverde collectiedata:
Om valide te zijn moet je CSV-bestand:
- de juiste velden bevatten. Een veld te veel of te weinig zal resulteren in een niet-valide CSV-bestand.
- een komma of puntkomma als scheidingsteken hebben. Indien je CSV-bestand een ander scheidingsteken bevat, kan je dat op een eenvoudige manier omzetten, bijvoorbeeld m.b.v. Google Spreadsheet: importeer je CSV-bestand in een Google Spreadsheet en download vervolgens als CSV-bestand:
De eerste rij van je CSV-bestand bevat de veldnamen zoals aangegeven in onderstaande templates. Per rij moet enkel de identifier verplicht ingevuld zijn. Verder geldt: hoe meer ingevulde velden, hoe beter de resultaten die deze tool zal opleveren.
Aan de inhoud van elk veld zijn een aantal vereisten verbonden:
Formaat: url (publiek toegankelijke unieke URL voor het collectie-item), indien niet beschikbaar een string met het inventarisnummer
Een string die zegt wat voor soort object het werk is, bv. een schilderij, standbeeld, etc.
Formaat: string
In gevallen waarbij het om een uitgegeven werk gaat, kan dit ook een publicatiedatum zijn.
Mogelijke formaten:
(de importer zal deze omzetten naar yyyy/mm/dd)
- yyyy-mm-dd
- yyyy-mm
- yyyy
- circa yyyy
- ca yyyy
- ca. yyyy
Formaat: string
Voor- en achternaam van de rechthebbende vervaardiger van het werk, liefst in die volgorde en zonder komma's (dus: liever "Jan Janssens" dan "Janssens, Jan"). Hou dit veld zo zuiver mogelijk, dus zonder extra toevoegingen of notities zoals een geboorteplaats, werkgever,... Wanneer de rechthebbende een organisatie is, geef je in dit veld de organisatienaam weer.
Formaat: string
Indien meerdere waarden voor dit veld worden deze uitgesplitst over meerdere rijen. De velden met betrekking tot het werk zullen identiek zijn voor de verschillende rijen.
Mogelijke formaten:
(de importer zal deze omzetten naar yyyy om zo de matching te doen):
- yyyy-mm-dd
- yyyy-mm
- yyyy
- circa yyyy
- ca yyyy
- ca. yyyy
Indien meerdere vervaardigers zal ook dit veld meerdere waarden hebben die worden uitgesplitst over meerdere rijen. De velden met betrekking tot het werk zullen identiek zijn voor de verschillende rijen.
Mogelijke formaten:
(de importer zal deze omzetten naar yyyy om zo de matching te doen):
- yyyy-mm-dd
- yyyy-mm
- yyyy
- circa yyyy
- ca yyyy
- ca. yyyy
Indien meerdere vervaardigers zal ook dit veld meerdere waarden hebben die worden uitgesplitst over meerdere rijen. De velden met betrekking tot het werk zullen identiek zijn voor de verschillende rijen.
De Wikidata-identifier van deze persoon. Deze kan ingevuld zijn door de instelling. Als dat niet het geval is, wordt het waar mogelijk door de tool aangevuld.
Formaat: Q + integer (bv. Q158840)
Indien meerdere vervaardigers zal ook dit veld meerdere waarden hebben die worden uitgesplitst over meerdere rijen. De velden met betrekking tot het werk zullen identiek zijn voor de verschillende rijen.
De VIAF-identifier van deze persoon.
Formaat: integer (bv. 88625859)
Indien meerdere vervaardigers zal ook dit veld meerdere waarden hebben die worden uitgesplitst over meerdere rijen. De velden met betrekking tot het werk zullen identiek zijn voor de verschillende rijen.
De RKD-identifier van deze persoon.
Formaat: integer (bv. 88625859)
Indien meerdere vervaardigers zal ook dit veld meerdere waarden hebben die worden uitgesplitst over meerdere rijen. De velden met betrekking tot het werk zullen identiek zijn voor de verschillende rijen.
Formaat: integer (bv. 88625859)
Indien meerdere vervaardigers zal ook dit veld meerdere waarden hebben die worden uitgesplitst over meerdere rijen. De velden met betrekking tot het werk zullen identiek zijn voor de verschillende rijen.
De betrouwbaarheid van de inschattingen over de auteursrechtelijke status van je collectiestukken die deze tool oplevert, hangt in grote mate af van de beschikbare data. Dat betreft zowel de data waarover je zelf beschikt als de data die uit Wikidata worden opgehaald. We raden je daarom aan om:
- enkel gegevens in je export te laten staan waarvan je zeker bent;
- de voorgestelde matches met items in Wikidata zorgvuldig te valideren.
De tool maakt een aantal berekeningen op basis van de aangeleverde data. Die berekeningen zijn gebaseerd op de wettelijke beschermingstermijnen. Bij gebrek aan een sterfdatum van een vervaardiger gebeurt een inschatting op basis van geboortedatum of creatiedatum. In beide gevallen wordt gekeken of die datum al langer dan 170 jaar in het verleden ligt om de status “publiek domein” toe te kennen.
De Publiekdomeintool kan niet nagaan of de aangeleverde data correct en volledig zijn. Wanneer van een werk dat door een duo is gemaakt bijvoorbeeld maar één van beide vervaardigers (met een sterfdatum voor 1950) in de data is opgenomen zal het werk foutief als in het publiek domein worden bestempeld als de tweede vervaardiger pas in 1960 is overleden (en NIET in de data is opgenomen). Die analyse wordt lijn per lijn in het CSV-bestand gemaakt. Hou er dus rekening mee dat bij collectie-items met meerdere vervaardigers of rechthebbenden alle rijen met betrekking tot dit item de status “publiek domein” zullen moeten hebben om het collectiestuk als publiek domein te beschouwen.
De Publiekdomeintool maakt niet alleen gebruik van jouw data, maar ook van Wikidata. Een wereldwijde gemeenschap werkt permanent aan de betrouwbaarheid van Wikidata als informatiebron. Ook gereputeerde instellingen en organisaties als bv. de Library of Congress, de Association of Research Libraries, IFLA als PCC (Program for Cooperative Cataloging) dragen daaraan bij. Mocht je foute informatie aantreffen in Wikidata, wees dan collegiaal, corrigeer de data en voorzie ze van een bronvermelding.
Kort samengevat: de berekeningen zelf zijn betrouwbaar, maar je blijft als collectiebeheerder steeds zelf verantwoordelijk om een voorgestelde status al dan niet voor waarheid aan te nemen. Een goede inschatting van de volledigheid en correctheid van je data is daarbij cruciaal. Zie ook deze disclaimer.
